-
클라우드 컴퓨팅 기반 유전체 정보 관리 및 서비스 동향Finance/Economy 2021. 1. 3. 00:20
클라우드 컴퓨팅 기반 유전체 정보 관리 및 서비스 동향
하드웨어의 발전으로 스토리지 및 네트워크 대역폭의 비용이 내려가고 있으며 차세대 게놈 시퀀싱의 비용도 급감하고 있다. 또한 최초의 인간 게놈 데이터를 만드는 작업은 수십 년이 걸렸지만 이제 수일 내에 풀 시퀀싱이 가능함에 따라 유전체 데이터는 기하 급수적으로 증가하고 있다. 그러나 현실적으로 유전체 연구에 필요한 통계 능력을 확보하는 데 필요한 게놈 데이터 및 관련 임상 데이터의 양이 단일 서버의 처리 능력을 초과한다. 그 대안으로 클라우드 컴퓨팅 서비스를 이용하면 직접 머신을 구매하거나 관리할 필요 없이 사용한 만큼만 비용을 지불하면 되는 장점이 있다. 연구자들은 클라우드 컴퓨팅 서비스로 대규모 유전체 유전체학, 시스템 생물학, 생물 의학 분야의 데이터를 쉽게 접근하여 통합적으로 관리, 분석, 공유할 수 있다. 이러한 클라우드 컴퓨팅 서비스는 유전체 정보 관리 및 분석을 위해 점차 확대되고 있으며 국내외의 클라우드 컴퓨팅 기반 유전체 서비스 동향에 대해서 살펴보고자 한다.
생명정보 분야의 클라우드 서비스의 대두 1990년 초, 미국을 중심으로 한 다국적 컨소시엄에서 최초의 인간 게놈 데이터를 만드는 작업은 수백명의 인원이 투입되어 10년 이상의 기간과 1,000억원 이상의 비용이 소요되었다. 차세대 게놈 시퀀싱(Next Generation Sequencing, NGS)의 기술이 발전해 나감에 따라 2011년 스티브 클라우드 컴퓨팅 기반 유전체 정보 관리 및 서비스 동향 김가경 Page 5 / 20 잡스가 췌장암 치료를 위해 풀시퀀싱 유전자 검사비로 10만 달러를 사용했던 것이 지금은 1,000달러 이내로 가능하며 지난 1월 열린 JP모건 헬스케어 컨퍼런스에서 Illumina가 NovaSeq 6000을 발표하면서 100달러 게놈 시대가 열렸다. 이렇듯 NGS의 비용이 낮아짐에 따라 생산되는 유전체 데이터가 기하 급수적으로 증가하고 있다. 유전체 연구를 위해선 1인당 약 300GB에 달하는 데이터를 분석해야 연구에 필요한 결과를 정확히 추출할 수 있다. 10명이면 3TB, 100명이면 약 30TB에 이르는 데이터를 분석해야 한다. 30TB는 MP3 음악파일 75만곡을 저장할 수 있는 분량이다. IT 전문 인프라가 부족한 의료기관이나 연구기관이 이러한 대용량 유전체 데이터를 개별 시스템을 구축해 효율적으로 관리하고, 최신의 분산병렬 컴퓨팅 기술을 이용한 데이터 전송 및 저장에 많은 어려움이 있다. 그러나 클라우드 서비스를 통해 개인이 유전자 분석을 할 수 있고, 정보를 저장할 수 있다. 전통적인 생물정보학과 새로운 클라우드 기반 워크플로우 사이에는 차이점이 있다. 전통적인 경우 데이터를 가공, 분석 및 결과 획득을 위해 연구자가 자신의 컴퓨터와 같은 저장 장치에 직접 다운로드 하거나 업로드 하는 과정을 거침에 따라 일반적으로 느리고 중복되며 높은 IT 자본 지출을 필요로 한다. 반면에, 새로운 클라우드 컴퓨팅 유전체학 모델은 데이터를 다운로드 하는 대신 컴퓨팅(예: 표준 및 사용자 지정 파이프라인, 워크플로우 도구)이 데이터에 제공되는 원 스톱 워크플로우가 특징이다. 또한 과학 연구에서 전통적인 방법에 비해 클라우드 컴퓨팅의 솔루션을 통해 재현 가능한 과학 연구가 가능하다.
데이터 공유
-전통적인 방법
• 대형 데이터 세트는 표준 인터넷 연결을 통해 공유하기 어려우므로 많은 양의 기술 자원을 확보하고 저장해야 함
• 공용 데이터 세트가 자주 변경되며, 분석에 사용되는 전체 데이터 저장소를 보관하고 공유하기 어려움
-클라우드 컴퓨팅
•대형 데이터 세트는 클라우드의 'omnipresent' 리소스로 저장 될 수 있으며 클라우드의 모든 지점에서 직접 쉽게 복사하고 액세스 할 수 있음
• 대규모 공공 데이터 세트의 '스냅 샷'을 신속하게 복사, 보관 및 참조 가능접근과 보존
-전통적
• 자금 지원이 중단된 소프트웨어 또는 유지 관리자가 프로젝트를 중단한 후에는 소프트웨어 및 데이터 저장소가 퍼블릭 도메인에서 사라지는 경우가 있음. 이는 리소스에 대한 엑세스 및 공공 투자의 손실을 가져옴-클라우드 컴퓨팅
• 연구비로 지원되는 프로젝트의 소프트웨어, 코드 및 데이터를 보관하고 클라우드에서 공개적으로 액세스할 수 있는 리소스로 제공하고 자금을 지원함 • 클라우드 컴퓨팅 제공 업체가 공개 과학 데이터 세트를 무료로 호스팅DNAnexus 플랫폼의 특징은 다음과 같다.
• 세분화된 인증 및 접근 제어
• 재현성 있고 버전 제어 된 분석 결과
• 보안 및 개인 정보 보호 준수
• 재현성 및 문서화
• 공동 작업자 액세스의 보안 제어 및 감사
• Application Programming Interface (API) 기반의 Laboratory Information Management System (LIMS) 통합A. 게놈 센터의 다양한 요구를 위한 단일 플랫폼에 대한 지원
DNAnexus에서는 시스템에서 작동하는 코드의 문법을 기술하는 API 기반 플랫폼을 통해 게놈 센터 및 연구실의 다양한 요구에 대해 현재 프로세스와 워크플로우를 클라우드로 마이그레이션할 수 있는 유연성을 제공한다. 각 프로젝트의 요구 사항을 충족시키기 위해 DNAnexus 플랫폼은 수백 명의 공동 연구자를 추가하여 여러 연구자에 대한 통합 지원을 제공한다. 액세스 제어 및 자원 제한은 상세한 가시성 및 제어를 위해 사용자, 조직 및 프로젝트 레벨에서 적용될 수 있다. Linux 쉘 형식의 명령을 줄 도구와 웹 환경이 편리한 온라인 인터페이스를 모두 제공한다.
B. 대규모 게놈 데이터 세트 및 복잡한 파이프라인 관리
풍부한 API를 제공하기 때문에 LIMS 시스템을 통해 프로그래밍 방식으로 액세스할 수 있다. 사용자는 보관 정책 및 삭제 정책 시행, 데이터 태그 지정 및 검색, 사용 보고서 생성 및 파이프라인 실행 자동화와 같은 작업을 쉽게 수행할 수 있다. 하나의 안전한 환경 아래에서 데이터 및 전산 도구를 사용하면 복제 또는 불필요한 데이터 전송 없이 재현 가능하고 버전 제어된 분석 결과를 쉽게 얻을 수 있다. The Baylor College of Medicine Human Genome Sequencing Center (BCM-HGSC)에서 대규모 게놈 분석 문제를 보다 빠르고 비용 효과적으로 해결하고 달성하는 데 도움이 되는 클라우드 컴퓨팅의 응용 분야에서 발전을 가져왔다. 이러한 선구자적 연구를 통해 HGSC와 함께 Mercury variant-calling[7] 파이프라인을 DNAnexus 플랫폼에 배치하여 14,000개 이상의 게놈에 대한 데이터 분석을 확장하기도 하였다.그 밖에 DNAnexus의 사례 연구 중에 2015년 6월 스탠포드 대학의 Data Coordination on Center (DCC)의 ENCyclopedia of DNA Elements (ENCODE) 프로젝트가 있다[8]. DNAnexus 플랫폼은 ENCODE 데이터에 대한 DCC 생물 정보 분석을 지원하므로 광범위한 연구 커뮤니티에서 소규모 기업의 생물 정보 방법을 사용할 수 있다. 수천 개의 데이터 세트를 처리할 수 있는 확장 가능한 솔루션이 DCC의 핵심 요구 사항이며 버전 제어 파이프라인의 개발을 통해 현재 단계에서 대중에게 공개되는 ENCODE 프로젝트의 데이터가 일관되게 처리되도록 한다. 균일한 메타 데이터 표준 및 생물 정보 분석을 사용하여 프로젝트의 미처리 및 처리된 시퀀스 기반 데이터를 중앙 집중화하는 작업을 수행한다.
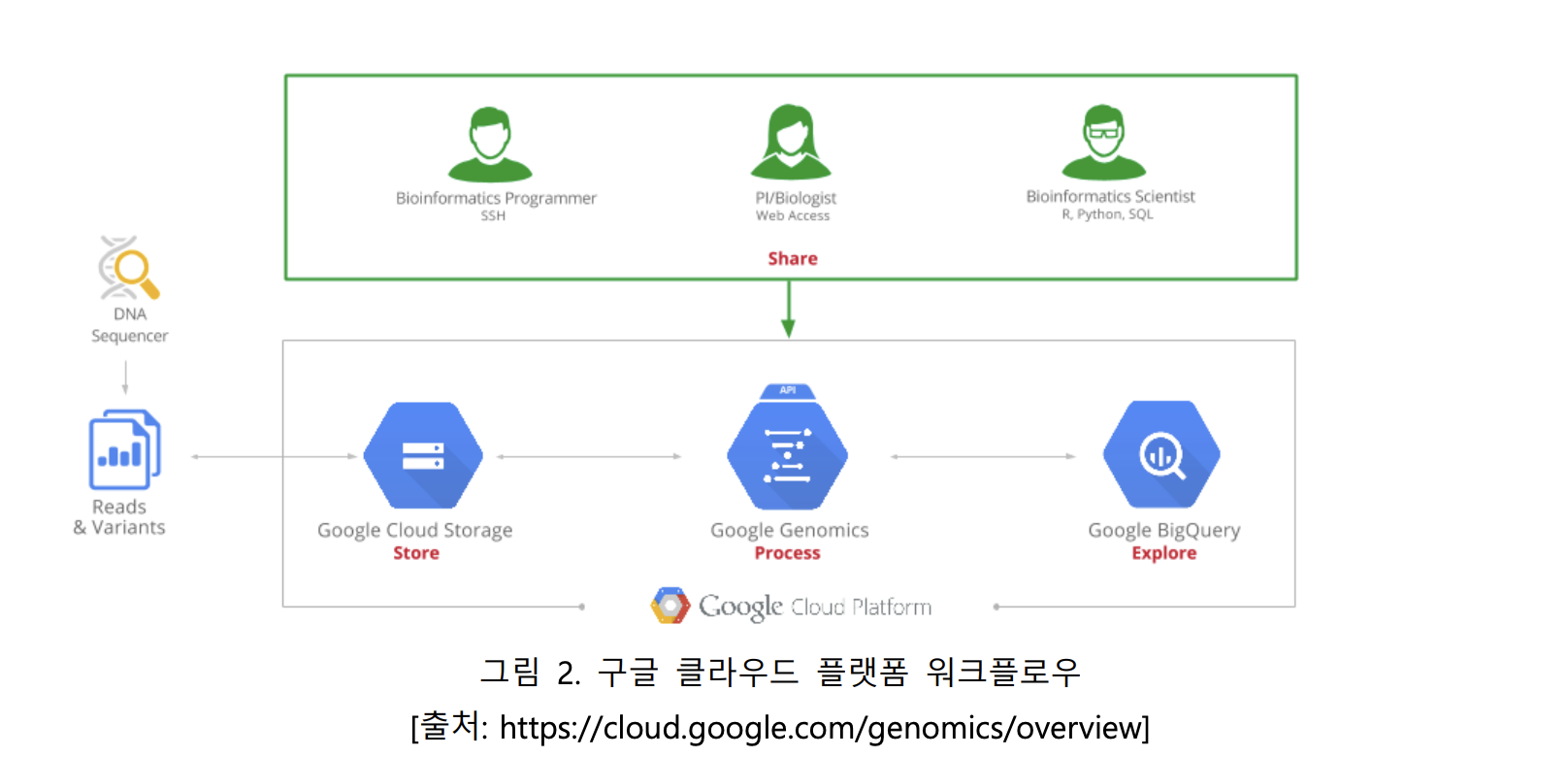
구글은 2008년에 가상 플랫폼 서비스(PaaS)인 구글 앱엔진을 출시했다. 구글 클라우드는 구글의 그 동안 검색, 지도, 유튜브에서 축적한 기술을 가지고 데이터 센터 인프라를 기반으로 연산, 저장소, 네트워킹, 빅데이터, 기계학습 등의 서비스를 제공하는 글로벌 클라우드다. 구글 지노믹스 (Google Genomics)는 구글 서버 안에서 클라우드 시스템을 구축하여 유전자 분석을 할 수 있도록 하고, 정보를 저장할 수 있게 해준다[9]. 이 서비스의 출발은 National Cancer Institute에서 시작한다. 환자 데이터 분석을 하기 위해 The Cancer Genome Atlas (TCGA) 프로젝트를 구성하여 약 13,000여명의 암환자에 대한 대규모 데이터를 분석할 수 있는 회사들과 파일럿 프로젝트를 하였고, 그 중 구글이 선정되었다. 유전자 분석을 통해 맞춤형 의료(Precision Medicine)을 하려는 스탠포드 대학병원에서 최근 구글 클라우드를 이용하여 환자들의 유전자 패턴을 분석(Molecular Profiling)하겠다고 밝혔다 (http://www.mayoclinic.org/diseases-conditions/cancer/expert-blog/molecular-profiling/bgp20056382). 스탠포드 대학 병원 의사들은 필요에 따라 환자의 시퀀싱을 의뢰할 수 있으며, 이 데이터는 구글 지노믹스 안에서 익명의 다른 스탠포드 환자들의 데이터와 비교 분석된다. 특정 동일 경력을 공유하는 집단과의 분석(예: 대장암을 겪은 집단)을 통해 현재 환자와 가장 유사한 사례를 찾아 처방을 내려 치료의 정확도를 높이는 것이 궁극적인 목적이다. 이 외에도 구글 지노믹스 시스템 안에서 개발된 분석 도구들은 다른 기관 간에도 전문 IT 기술 없이 쉽게 공유가 가능하다. 하드웨어적으로는 Google Compute Engine Virtual Machine (VM) 기술을 이용하여 수천 대에서 수 만대의 컴퓨터를 유저들이 동시 다발적으로 유전자 분석을 할 수 있기 때문에 분석 시간을 대폭 단축시켜준다. 구글 지노믹스를 통해 페타바이트 크기의 거대한 유전체 데이터의 서열 읽기, 변이, 레퍼런스 및 주석의 모든 과정을 분석할 수 있으며 다음과 같이 활용할 수 있다
회사명 웹사이트 특징 FireCloud https://software.broadinstitute.org/firecloud/ Broad Institute 의 클라우드 기반 TCGA 데이터에 대한 암 게놈 분석 플랫폼 BaseSpace http://basespace.illumina.com Illumina 클라우드 기반의 NGS 데이터 관리 및 분석을 위한 유전체 컴퓨팅 환경 Seven Bridges Genomics http://www.sbgenomics.com NCI Cloud Genomics Pilot 의 혁신적인 플랫폼을 구축 (October 21, 2014 — Cambridge, MA) Curoverse http://curoverse.com 테라 바이트에서 페타 바이트까지의 데이터를 관리 및 처리하는 최신 오픈 소스 컴퓨팅 시스템 인 Arvados 를 사용하여 주요 클라우드에서 실행 InsideDNA https://insidedna.me/ 웹 브라우저 또는 터미널 유틸리티를 통해 유전체 데이터를 업로드하고, 1000 개 이상의 생물 정보 도구를 이용하여 CPU 와 RAM 결정 후 결과를 빠르고 쉽게 얻을 수 있으며, 간단한 웹 URL 로 저장되는 iMethod 로 분석을 저장하고 공유가 가능 Pine Biotech http://pine-biotech.com/ 간단한 인터페이스와 직관적인 옵션을 통해 오믹스 데이터 및 기계 학습 방법의 분석은 물론 모델링을 결합하여 다양한 데이터 유형에 대한 분석을 통합 BGI Online https://www.bgionline.com/ 설치가 필요 없는 게놈 시퀀싱 및 분석 프로젝트에 도움을 주는 안전한 클라우드 플랫폼 GenoSpace http://www.genospace.com 종양학 및 희귀 질병에 대한 정밀 의학을 위한 클라우드 기반 소프트웨어 Cypher Genomics http://www.cyphergenomics.com 대규모 컴퓨팅 및 기계 학습을 개발 및 적용하여 전체 게놈, 표현형 및 임상 데이터에 대한 세계에서 가장 크고 가장 포괄적 인 데이터베이스를 만든 Human Longevity, Inc. (HLI)와 협력 Era7 http://era7.com NGS, 박테리아 유전체, 클라우드 컴퓨팅, 오픈 서비스를 지향하는 NGS 프로젝트 통합 분석 서비스 제공 Genestack http://www.genestack.com 유연한 데이터 관리 인프라, 시각적 분석 도구, 파이프라인 및 보고서를 제공하는 생물정보학 플랫폼 PierianDx http://pieriandx.com/ 학술 의료 센터, 보건 시스템, 어린이 병원, 종합 암 센터 및 상업 실험실을 통해 정밀 의약 사업을 가속화. 임상 검사를 사내에서 신속하게 또는 한 번에 한 단계 씩 수행하려는 경우 적절한 솔루션을 제공 Eagle Genomics http://www.eaglegenomics.com 데이터 관리 솔루션은 유전체학 연구에 의해 생성 된 기하 급수적으로 증가하는 데이터 양을 효율적으로 분석하고 관리 할 수 있음 Maverixbio http://www.maverixbio.com 최적의 NGS 데이터 분석 기능을 제공하는 연구원 및 의료 서비스 제공 업체를 지원하여 기존 병목 현상을 극복하고 발견 및 진단 결과의 속도를 가속화